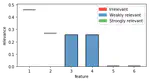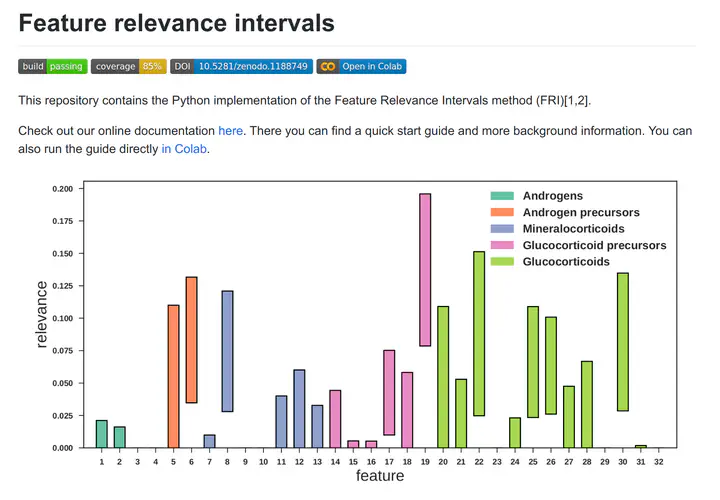
Feature selection is the task of finding relevant features used in a machine learning model. Often used for this task are models which produce a sparse subset of all input features by permitting the use of additional features (e.g. Lasso with L1 regularization). But these models are often tuned to filter out redundancies in the input set and produce only an unstable solution especially in the presence of higher dimensional data.
FRI calculates relevance bound values for all input features. These bounds give rise to intervals which we named ‘feature relevance intervals’ (FRI). A given interval symbolizes the allowed contribution each feature has, when it is allowed to be maximized and minimized independently from the others. This allows us to approximate the global solution instead of relying on the local solutions of the alternatives.
Dr. Lukas Pfannschmidt
Tech Lead, Machine Learning Platform
Tech Lead of the Machine Learning Platform team at Trade Republic, supporting FinCrime. Research background (PhD) in machine learning with prior work in high‑performance computing. I focus on platform strategy for ML systems, shipping reliable ML/analytics pipelines, reducing latency and cost, and tightening feedback loops between models, data pipelines and observability.